
Comparing Open AI GPT models for email generation
There are many GPT models to choose from. The AI plugin for Mautic was using several versions of GPT 3.5-turbo in the past. We've been testing v4 a couple months ago but it was way too slow and the results were worse than with version 3.5. The models evolve incredibly fast though, so we set down to compare them and find the best one for generating email content for Mautic.
The prompt used for testing
We used this same prompt for our GPT model testing:
Generate an email to promote a Stripe payment plugin allowing you to sell digital products in Mautic. Use tokens {contactfield=firstname}, {unsubscribe_text} and a call to action button with link to {pagelink=1}.
GPT models
Each model has pros and cons. The main problem we wanted to solve was that some models are getting end of life and they are often way too slow to work with.
GPT 3.5
The GPT-3.5 models possess the remarkable capability to generate code and exhibit a foundational understanding of various natural languages.
gpt-3.5-turbo
This model points to gpt-3.5-turbo-0613 which will not be supported after June 2024. The API response takes around 1 minute which is painful to work with and can lead to timeouts which degrades user experience. The training data here extends up to September 2021. The maximum token limit for processing stands at 4,096, enabling the model to effectively handle inputs of a certain length or complexity.
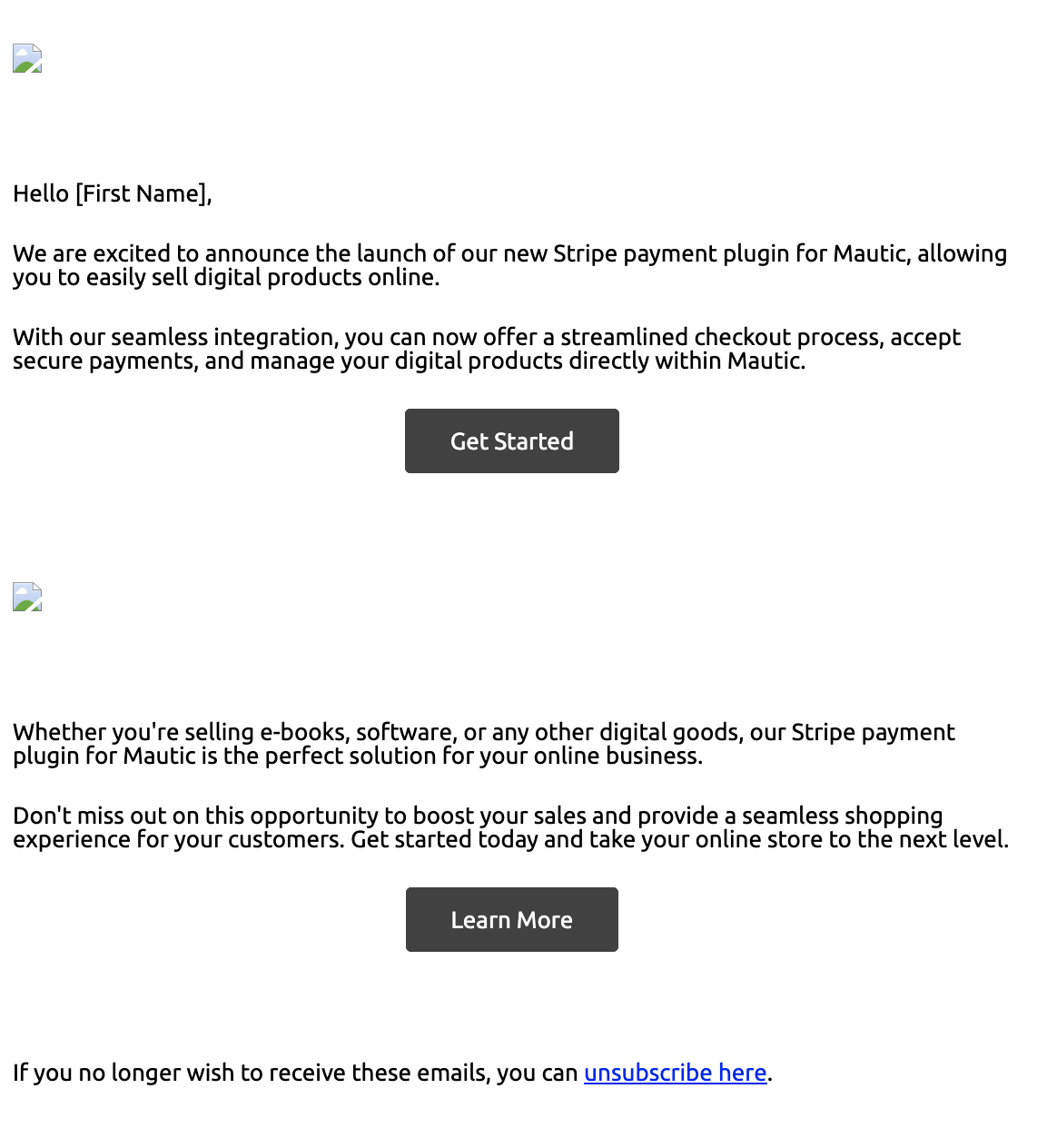
Here is an example of generated email content.

This is already a preview of the email so the unsubscribe token was replaced with the right text and the {contactfield=firstname} was switched to [First Name].
Notice that the model suggested an image in the email but it cannot work with images so it leads to an example URL.
gpt-3.5-turbo-1106
Representing the most recent addition to the GPT 3.5 model family, this model has training data up to September 2021, aligning its knowledge with developments and information available until that period. Notably, this iteration features an expanded token limit, capable of processing a maximum of 16,385 tokens, thus accommodating longer and more intricate inputs compared to prior models in the series.
Here is an example of generated email content.
GPT 4
Model GPT-4 represents a significant advancement over GPT-3.5, offering enhanced capabilities and features. This iteration of the model introduces the ability to process both text and image inputs while producing text-based outputs. GPT 4 possesses an updated understanding of language nuances and trends, enabling it to tackle complex tasks more effectively. Its extended exposure to recent data enhances its adaptability and comprehension of contemporary information.
gpt-4
Model gpt-4 refers to gpt-4-0613. The model's training data includes information up to September 2021, providing a comprehensive understanding of language patterns and structures up to that point in time. This model is optimised to process a maximum of 8,192 tokens.
Here is an example of generated email content.
gpt-4-1106-preview
The most recent GPT-4 model increases such as refined instruction following, compatibility with JSON mode, outputs that can be reproduced consistently, and the capability for parallel function calling, among other improvements. It delivers a maximum of 4,096 tokens in its standard output, providing concise yet informative responses. The model has been trained with data up to April 2023, ensuring it has an updated understanding of recent information and trends.
It's worth mentioning that this model is currently undergoing continuous development and refinement, thus not yet tailored for handling production-level traffic. For more extensive tasks or specialized applications, it has the capacity to process a maximum of 128,000 tokens, allowing for significantly longer text inputs and outputs.
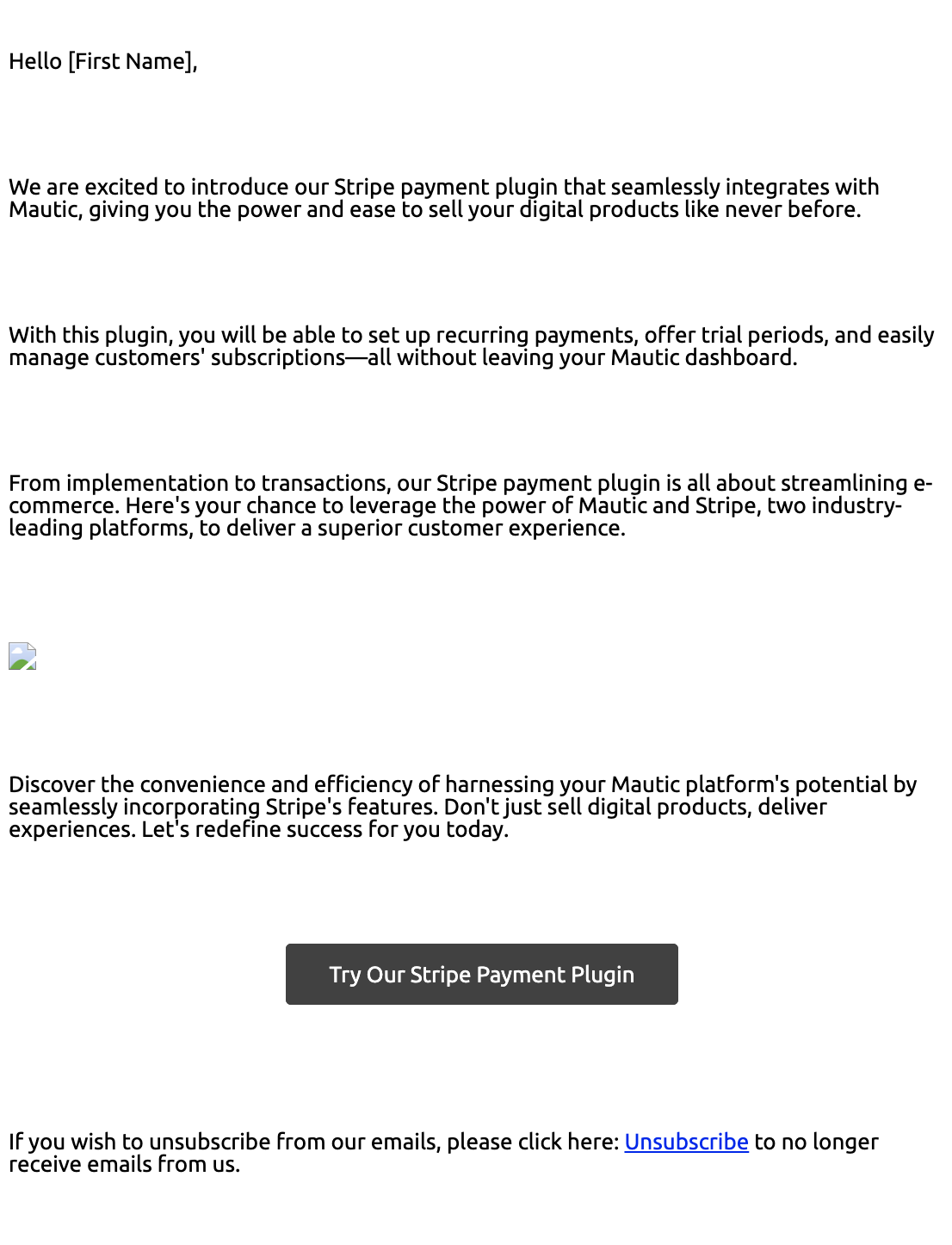
Here is an example of generated email content.

Interesting here is that this model is using a free service that can generate images in specific dimension. You can tell the previous models to use that service too, but this one is using it by itself. It also adds some color without asking for it.
Testing the models
In our test we took the same prompt and asked each model 6 times to generate an email. We were. mostly curious about:
- how long the prompt request takes,
- how many tokens was used (prompt was the same: 154 tokens),
- total cost for all used tokens with all prompt requests,
- Quality of the generated email.
| gpt-3.5-turbo-0613 | gpt-3.5-turbo-1106 | gpt-4 | gpt-4-1106-preview | |||||
| duration | used tokens | duration | used tokens | duration | used tokens | duration | used tokens | |
| 1. | 1,4 min | 049 | 6,94 s | 449 | 22,62 s | 563 | 54,9 s | 751 |
| 2. | 43,08 s | 472 | 11,06 s | 648 | 27,53 s | 620 | 48,54 s | 727 |
| 3. | 1,6 min | 923 | 6,98 s | 427 | 24,99 s | 613 | 45,62 s | 676 |
| 4. | 39,4 s | 822 | 12,55 s | 570 | 23,59 s | 608 | 57,13 s | 716 |
| 5. | 2,4 min | 1495 | 12,15 s | 556 | 20,13 s | 567 | 41,41 s | 763 |
| 6. | 36,26 s | 731 | 7,65 s | 391 | 21,42 s | 592 | 52,33 s | 643 |
| cost | 0,02 USD | 0,02 USD | 0,09 USD | 0,11 USD | ||||
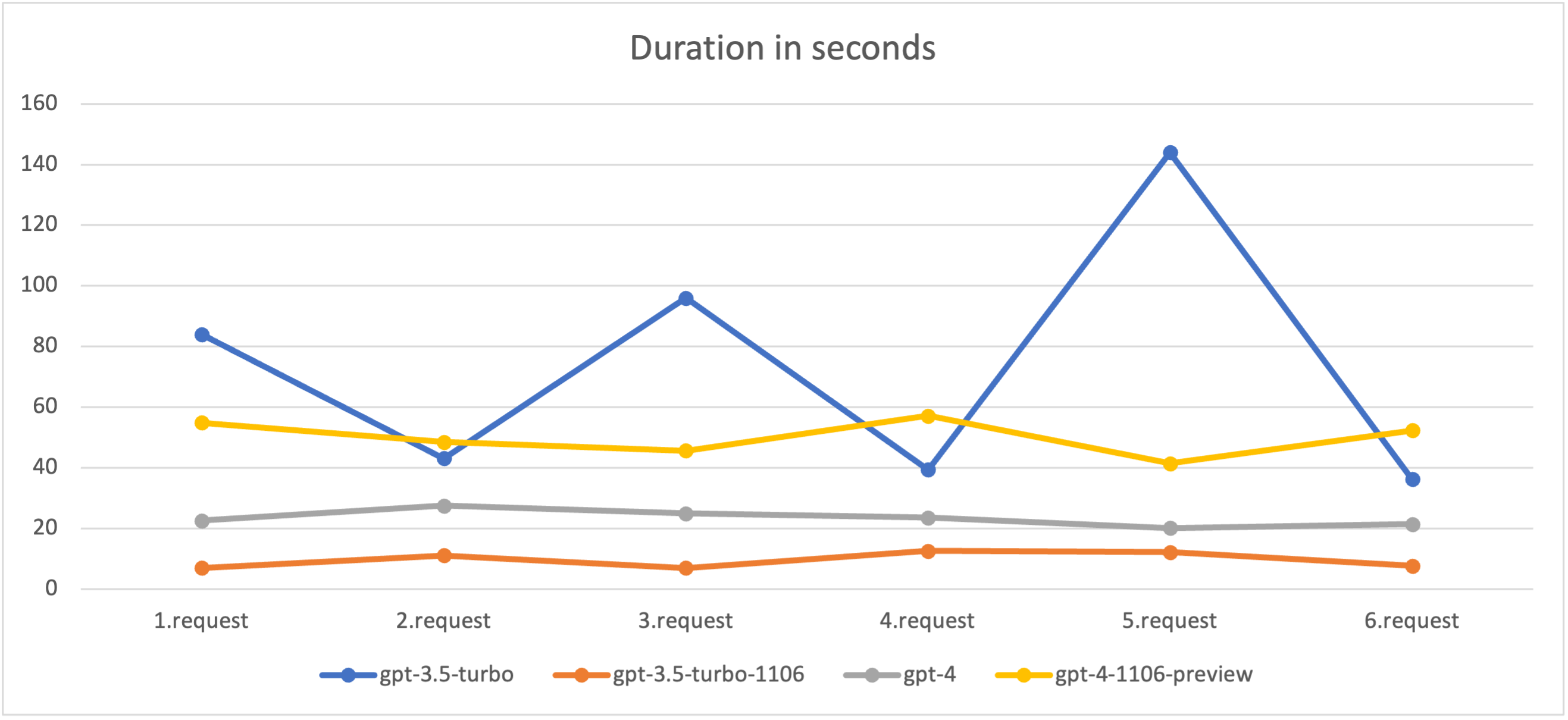
The fastest is gpt-3.5-turbo-1106 and it uses smallest amount of tokens. Although you can tell how long you want the response and each model will try to give you the length you expect. The response is graphically simpler and cheaper than gpt-4-1106-preview,
| gpt-3.5-turbo | gpt-3.5-turbo-1106 | gpt-4 | gpt-4-1106-preview | |
| cost per 1000 tokens | 0,003642 USD | 0,006577 USD | 0,006577 USD | 0,025725 USD |
| average token usage | 915,33 | 506,83 | 593,83 | 712,67 |
| average time | 73,79 s | 9,56 s | 23,38 s | 49,99 s |
The fastest model we tested is gpt-3.5-turbo-1106. If we consider that default timeout for HTTP requests is set to 30 seconds then gpt-3.5-turbo and gpt-4-1106-preview are unusable for our plugin unless you extend the timeout setting on your server.
Token consumption is different for each model. The biggest consumption is with gpt-3.5-turbo and the lowest consumption uses gpt-3.5-turbo-1106.
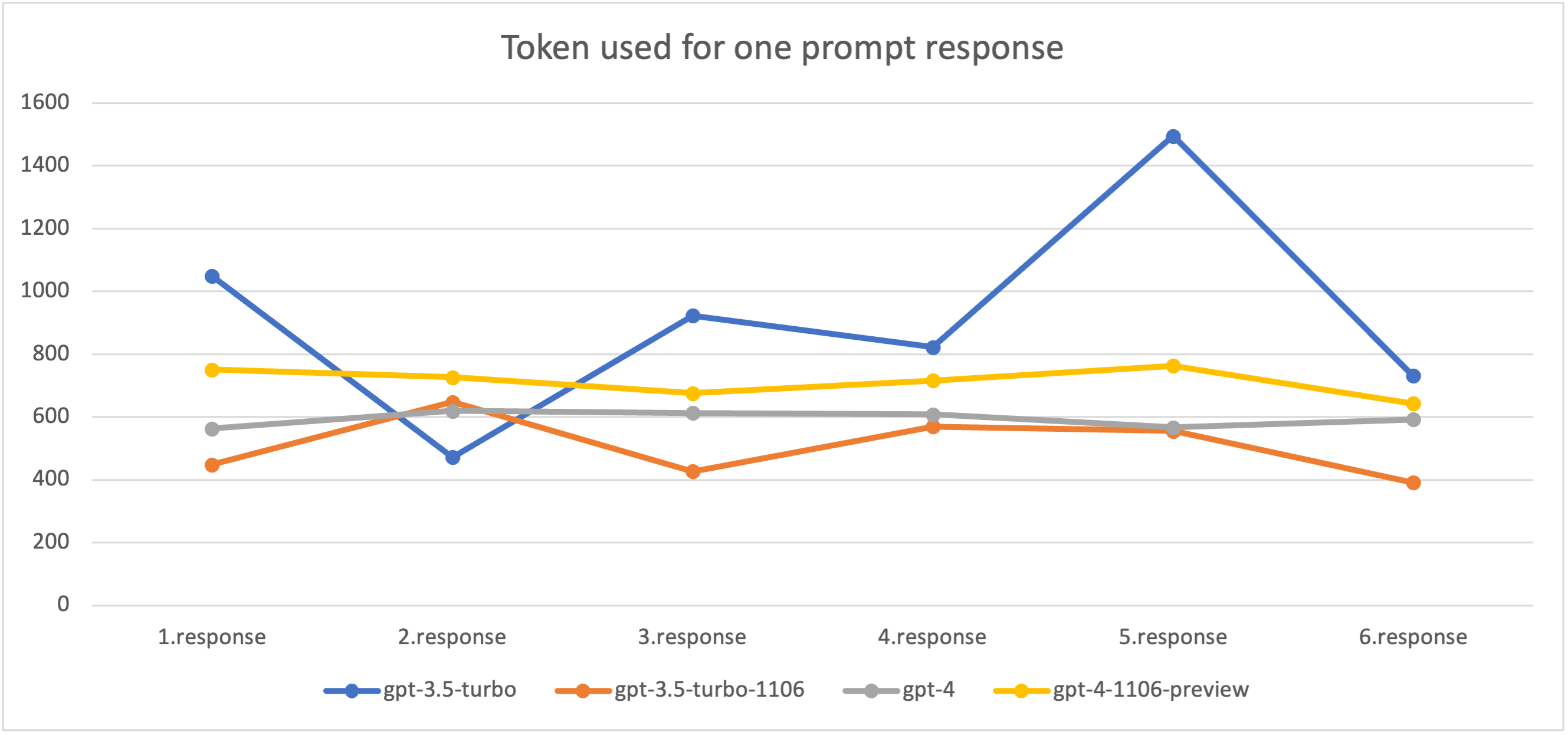
In the following graph we multiplied the tokens used with the price per token to get price per request. We find it interesting to compare with the chart above.
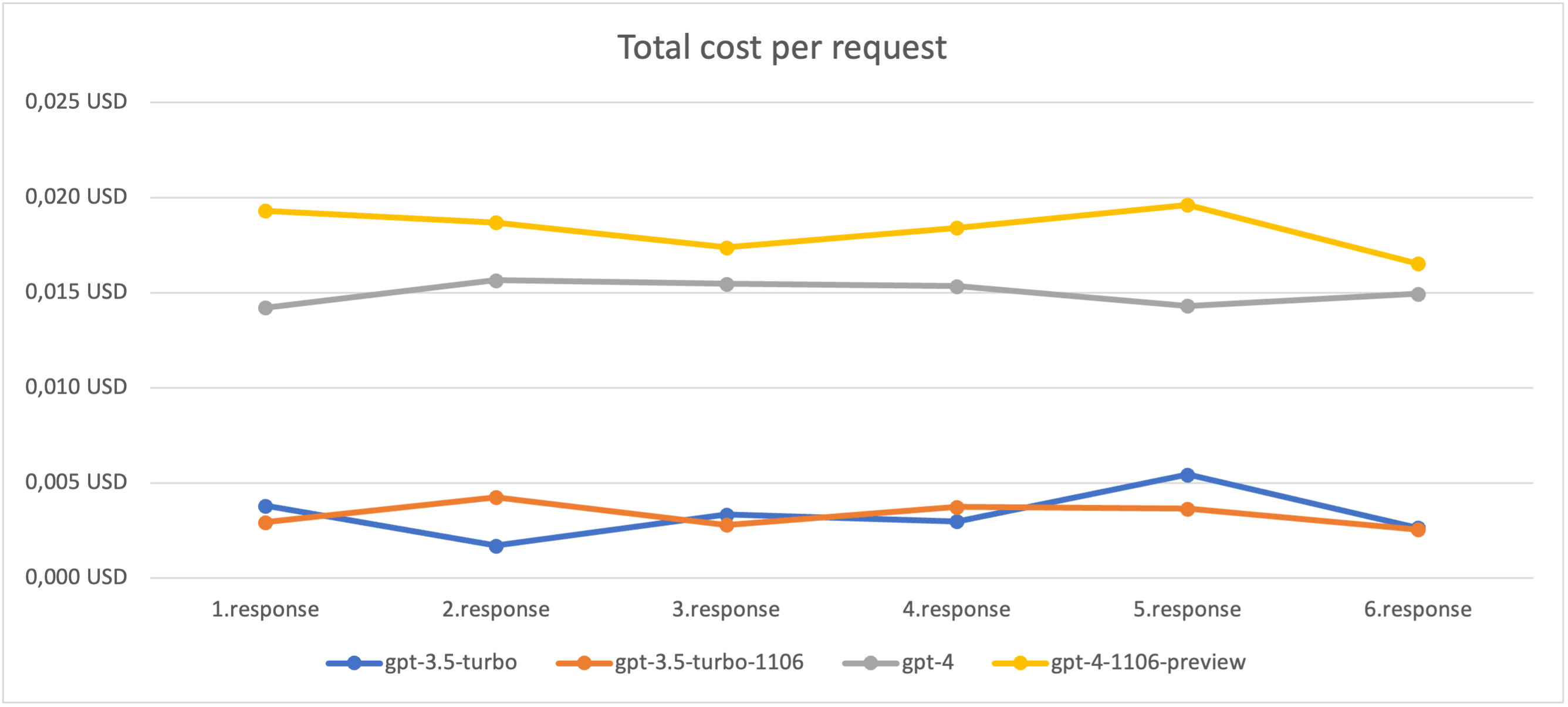
Conclusion
It is hard to choose the right model for our Mautic AI plugin. Everyone may prefer different characteristics. We ended up adding an option for our users to choose the right model for them from newer models gpt-3.5-turbo-1106, gpt-4 and gpt-41106-preview to the plugin configuration. The default model is set to gpt-4.
Model GPT 3,5 Turbo (gpt-3.5-turbo-1106) responses are simpler and less graphic, responses took less time and less token usage. Responses from GPT 4 Turbo (gpt-4-1106-preview) are more advanced response and better graphics, but it is more expensive with more token usage.
Understanding the strengths and limitations of each model is crucial in harnessing the full potential of generative AI. We can't wait to hear from users of our AI plugin about what model they've chosen. The new version of the AI plugin is already available and all existing customers have received it.